乐坛少有新歌,我经常听一些老歌,有时候顺着豆瓣音乐 Top 250 一点点听下去,感觉还是挺不错。
这中间一直有个麻烦地方:每次都要从豆瓣复制标题去 Apple Music 搜索。有没有简单便捷的方式直接一键抵达呢?
我没有找到答案,于是我自己整理了这批 Apple Music 链接,点击就可以直接跳转到 Apple Music 直接播放了
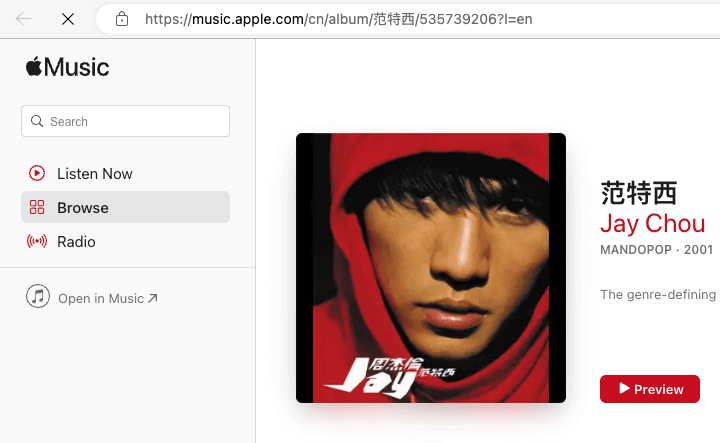
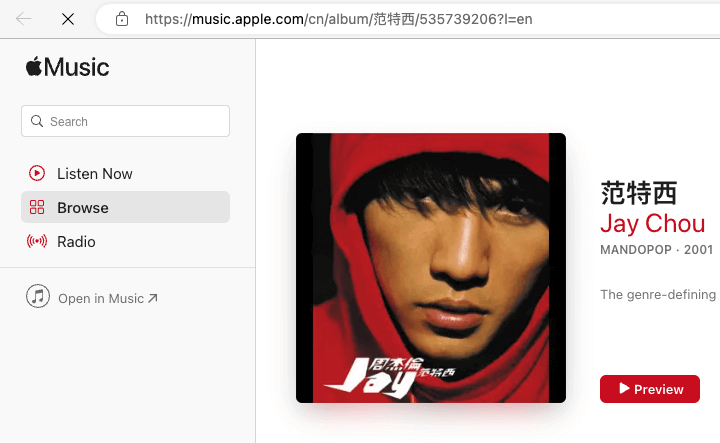
如上图所示,在本文点击「▶️ Apple Music」按钮,会打开 Apple Music 网站,点左侧的「Open in Music」即可在 Apple Music 打开。
PS:iPhone 上点击链接(Notes / Safari 等)会直接在 Apple Music 打开。
Update 2024-07:我提供了一个在线小网页可以随机选择一个专辑给你,并且一键播放 Apple Music。
Random Apple Music
源码 alswl/random-apple-music。
Jason Mraz / 2008-05-13 / Import / Audio CD / 民谣
9.1 ( 115738人评价 )

▶️ Apple Music
Coldplay / 2008-06-17 / 专辑 / CD / 摇滚
9.0 ( 117391人评价 )

▶️ Apple Music
陈绮贞 / 2005-09-23 / 专辑 / CD / 流行
9.0 ( 88220人评价 )

▶️ Apple Music
周杰伦 / 2001-09-14 / 专辑 / CD / 流行
9.5 ( 172202人评价 )

▶️ Apple Music
五月天 / 2008-10-23 / 专辑 / CD / 摇滚
9.0 ( 94647人评价 )

▶️ Apple Music
孙燕姿 / 2011-03-08 / 专辑 / CD / 流行
8.7 ( 81241人评价 )

▶️ Apple Music
Lenka / 2008-09-23 / 专辑 / Audio CD / 流行
8.6 ( 83181人评价 )

▶️ Apple Music
王若琳 / 2008-01-11 / 专辑 / CD / 爵士
8.8 ( 75301人评价 )

▶️ Apple Music
陈绮贞 / 2004-02-02 / 单曲 / CD / 流行
9.1 ( 98494人评价 )

▶️ Apple Music
陈绮贞 / 2009-01-22 / 专辑 / CD / 流行
8.7 ( 74979人评价 )

▶️ Apple Music
Glen Hansard,Marketa Irglova / 2007-05-22 / Soundtrack / CD / 原声
9.2 ( 72580人评价 )

▶️ Apple Music
Keren Ann / 2004-08-24 / Import / Audio CD / 民谣
8.9 ( 62347人评价 )

▶️ Apple Music
Green Day / 2004-09-21 / Explicit Lyrics / Audio CD / 摇滚
9.0 ( 72130人评价 )

▶️ Apple Music
张震岳 Csun Yuk / 2007-07-06 / 专辑 / CD / 流行
8.8 ( 81378人评价 )

▶️ Apple Music
苏打绿 / 2007-11-02 / 专辑 / CD / 流行
8.8 ( 89048人评价 )

▶️ Apple Music
张悬 / 2007-07-20 / 专辑 / CD / 流行
8.7 ( 64429人评价 )

▶️ Apple Music
张悬 / 2009-05-22 / 专辑 / CD / 流行
8.6 ( 62928人评价 )

▶️ Apple Music
Damien Rice / 2003 / 专辑 / CD / 流行
9.1 ( 52588人评价 )

▶️ Apple Music
Green Day / 2005-06-13 / 单曲 / CD / 摇滚
9.4 ( 54233人评价 )

nil
周杰伦 / 2003-07-31 / 专辑 / CD / 流行
9.2 ( 103849人评价 )

▶️ Apple Music
周杰伦 / 2004 / 专辑 / CD / 流行
9.1 ( 159642人评价 )

▶️ Apple Music
Adele / 2011-01-24 / 专辑 / CD / 流行
9.3 ( 72900人评价 )

▶️ Apple Music
张悬 / 2006-06-09 / 专辑 / CD / 流行
8.8 ( 56634人评价 )

▶️ Apple Music
王菲 / 2000 / 专辑 / CD / 流行
9.4 ( 66995人评价 )

▶️ Apple Music
苏打绿 / 2011-11-11 / 专辑 / CD / 流行
9.0 ( 57675人评价 )

▶️ Apple Music
林宥嘉 / 2009-10-30 / 专辑 / CD / 流行
8.6 ( 59038人评价 )

▶️ Apple Music
Nirvana / 1991 / 专辑 / CD / 摇滚
9.3 ( 62973人评价 )

▶️ Apple Music
周杰伦 / 2002-07-19 / 专辑 / CD / 流行
9.2 ( 87077人评价 )

▶️ Apple Music
周杰伦 / 2000-11-13 / 专辑 / Audio CD / 流行
9.3 ( 90828人评价 )

▶️ Apple Music
Coldplay / 2000-07-10 / 专辑 / CD / 摇滚
9.2 ( 54165人评价 )

▶️ Apple Music
孙燕姿 / 2000-12-7 / 专辑 / CD / 流行
9.0 ( 60779人评价 )

▶️ Apple Music
陈绮贞 / 2000 / 专辑 / CD / 流行
9.1 ( 51164人评价 )

▶️ Apple Music
Avril Lavigne / 2002 / Enhanced / Audio CD / 摇滚
8.9 ( 55425人评价 )

▶️ Apple Music
周杰伦 / 2005-11-01 / 专辑 / CD / 流行
8.9 ( 94955人评价 )

▶️ Apple Music
方大同 / 2008-12-19 / 专辑 / CD / 放克/灵歌/R&B
8.6 ( 49661人评价 )

▶️ Apple Music
苏打绿 / 2006-10-20 / 专辑 / CD / 流行
8.9 ( 51741人评价 )

▶️ Apple Music
蔡健雅 / 2009-08-19 / 专辑 / CD / 流行
8.1 ( 51151人评价 )

▶️ Apple Music
Lady & Bird / 2003 / Import / Audio CD / 民谣
8.8 ( 43532人评价 )
▶️ Apple Music
万能青年旅店 / 2010-11-12 / 专辑 / CD / 摇滚
9.5 ( 84135人评价 )
▶️ Apple Music
Linkin Park / 2003-03-25 / Enhanced / Audio CD / 摇滚
9.1 ( 45142人评价 )

▶️ Apple Music
James Blunt / 2004 / Explicit Lyrics / Audio CD / 流行
9.0 ( 43229人评价 )

▶️ Apple Music
苏打绿,蘇打綠 / 2005年9月 / 国语 / CD / 流行
8.9 ( 53849人评价 )

▶️ Apple Music
梁静茹 / 2009-01-16 / 专辑 / Audio CD / 流行
8.5 ( 46781人评价 )

▶️ Apple Music
林宥嘉 / 2011-05-06 / 专辑 / CD / 流行
8.7 ( 48384人评价 )

▶️ Apple Music
Yann Tiersen / 2001-04-23 / Soundtrack / Audio CD / 原声
9.4 ( 44514人评价 )

▶️ Apple Music
王若琳 / 2009-01-16 / 专辑 / CD / 爵士
8.3 ( 43076人评价 )

▶️ Apple Music
Tamas Wells / 2006 / Import / Audio CD / 民谣
9.0 ( 39351人评价 )

nil
田馥甄 Hebe / 2010-09-03 / 专辑 / CD / 流行
8.2 ( 45022人评价 )

▶️ Apple Music
孙燕姿 / 2007-03-22 / Import / CD / 流行
8.6 ( 69921人评价 )

▶️ Apple Music
王菲 / 1999-09-10 / Import / CD / 流行
9.4 ( 56383人评价 )

▶️ Apple Music
Chris Garneau / 2007-01-23 / 引进版 / Audio CD / 民谣
8.8 ( 39023人评价 )

nil
孙燕姿 / 2003-08-22 / 专辑 / CD / 流行
9.1 ( 42823人评价 )

▶️ Apple Music
陈奕迅 / 2003-11-20 / 选集 / CD / 流行
9.4 ( 42728人评价 )

nil
苏打绿 / 2009-05-08 / 专辑 / CD / 民谣
8.3 ( 45534人评价 )

▶️ Apple Music
盧廣仲 / 2008-5-27 / 专辑 / CD / 民谣
8.4 ( 42135人评价 )

▶️ Apple Music
梁静茹 / 2007-11-09 / 专辑 / CD / 流行
8.5 ( 49186人评价 )

▶️ Apple Music
陈绮贞 / 2005 / 选集 / CD / 民谣
9.2 ( 36799人评价 )

▶️ Apple Music
Joe Hisaishi / 1999-05-19 / 专辑 / CD / 原声
9.5 ( 49564人评价 )

▶️ Apple Music
Taylor Swift / 2008-11-11 / Enhanced / Audio CD / 流行
8.7 ( 53119人评价 )

▶️ Apple Music
Mika / 2007-02-05 / 专辑 / CD / 流行
8.8 ( 37038人评价 )

▶️ Apple Music
陈奕迅 / 2009-03-23 / 专辑 / CD / 流行
8.7 ( 44462人评价 )

▶️ Apple Music
林宥嘉 / 2008-06-03 / 专辑 / CD / 流行
8.5 ( 45772人评价 )

▶️ Apple Music
Bruno Coulais / 2004-05-03 / Soundtrack / Audio CD / 原声
9.5 ( 37888人评价 )

▶️ Apple Music
范晓萱&100% / 2009-08-10 / 专辑 / CD / 摇滚
8.2 ( 39589人评价 )

▶️ Apple Music
Damien Rice / 2006-11-06 / 专辑 / Audio CD / 民谣
9.0 ( 36862人评价 )

▶️ Apple Music
王菲 / 2003 / 专辑 / CD / 流行
8.9 ( 46704人评价 )

▶️ Apple Music
曹方 / 2005年12月 / 专辑 / CD / 流行
8.4 ( 39449人评价 )

nil
李志 / 2007-01-11 / CD / CD / 民谣
9.1 ( 51735人评价 )

nil
方大同 / 2009-08-11 / 自选集 / CD / 放克/灵歌/R&B
8.4 ( 38003人评价 )

▶️ Apple Music
周杰伦 / 2006-09-05 / 专辑 / CD / 流行
8.6 ( 71242人评价 )

▶️ Apple Music
孙燕姿 / 2001-07-09 / 专辑 / CD / 流行
8.9 ( 44131人评价 )

▶️ Apple Music
孙燕姿 / 2005-10-07 / 专辑 / CD / 流行
8.3 ( 45359人评价 )

▶️ Apple Music
The Weepies / 2006 / Import / Audio CD / 民谣
8.6 ( 39732人评价 )

▶️ Apple Music
陶喆 / 2002-08-09 / 专辑 / CD / 流行
9.1 ( 51691人评价 )

▶️ Apple Music
Avril Lavigne / 2004-05-12 / Import / Audio CD / 摇滚
8.6 ( 40059人评价 )

▶️ Apple Music
孙燕姿 / 2004-10-1 / 专辑 / CD / 流行
8.7 ( 39004人评价 )

▶️ Apple Music
Lady Gaga / 2008-08-19 / Import / Audio CD / 流行
8.5 ( 42436人评价 )

▶️ Apple Music
Jason Mraz / 2005-07-04 / Import / Audio CD / 流行
9.0 ( 34498人评价 )

▶️ Apple Music
五月天 / 2006-12-28 / 引进版 / CD / 流行
8.6 ( 40435人评价 )

▶️ Apple Music
Daniel Powter / 2006 / 专辑 / Audio CD / 流行
8.7 ( 35302人评价 )

▶️ Apple Music
Jason Mraz / 2008-12-16 / Single / Audio CD / 民谣
9.4 ( 39203人评价 )

▶️ Apple Music
许巍 Wei Xu / 2002-12-01 / 专辑 / CD / 民谣
9.1 ( 38564人评价 )

▶️ Apple Music
朴树 / 2003-11-28 / 专辑 / CD / 流行
9.0 ( 59817人评价 )

▶️ Apple Music
周杰伦 / 2007-11-01 / 专辑 / CD / 流行
8.2 ( 69903人评价 )

▶️ Apple Music
苏打绿 / 2009-09-11 / 专辑 / CD / 摇滚
8.7 ( 41388人评价 )

▶️ Apple Music
范晓萱 / 2001-08-25 / 专辑 / CD / 爵士
8.8 ( 35543人评价 )

▶️ Apple Music
曹方 / 2009-11-11 / 专辑 / CD / 流行
8.2 ( 33443人评价 )

▶️ Apple Music
孙燕姿 / 2003-01-10 / 专辑 / CD / 流行
8.7 ( 37301人评价 )

▶️ Apple Music
Radiohead / 1997 / 专辑 / Audio CD / 摇滚
9.4 ( 43284人评价 )

▶️ Apple Music
Lana Del Rey / 2012-01-31 / 专辑 / Audio CD / 流行
8.8 ( 48967人评价 )

▶️ Apple Music
Pink Floyd / 1979 / 专辑 / Audio CD / 摇滚
9.4 ( 45083人评价 )

▶️ Apple Music
痛仰 / 2008-10 / 专辑 / CD / 摇滚
8.7 ( 46100人评价 )

▶️ Apple Music
Linkin Park / 2000 / 专辑 / CD / 摇滚
9.0 ( 33231人评价 )

▶️ Apple Music
Nirvana / 1994-11-01 / Live / Audio CD / 摇滚
9.6 ( 34354人评价 )

▶️ Apple Music
陈绮贞 / 2004年12月 / EP / CD / 流行
9.2 ( 31467人评价 )

▶️ Apple Music
Jack Johnson / 2005-03-22 / 专辑 / Audio CD / 民谣
9.1 ( 29785人评价 )

▶️ Apple Music
五月天 Mayday / 2004-11-05 / 专辑 / CD+VCD / 流行
9.0 ( 35355人评价 )

▶️ Apple Music
五月天 / 2007-07-20 / 专辑 / CD+DVD / 流行
8.8 ( 41018人评价 )

▶️ Apple Music
陈奕迅 / 2008-06-30 / 专辑 / CD / 流行
8.4 ( 36475人评价 )

▶️ Apple Music
曲婉婷 / 2010-02-24 / 单曲 / 数字(Digital) / 流行
8.7 ( 46762人评价 )

▶️ Apple Music
Ennio Morricone / 1999-10-12 / Soundtrack / Audio CD / 原声
9.5 ( 35883人评价 )

▶️ Apple Music
张楚 / 1994 / 专辑 / CD / 摇滚
9.2 ( 39886人评价 )

▶️ Apple Music
徐佳莹 / 2009-05-29 / 专辑 / CD / 流行
8.4 ( 37502人评价 )

▶️ Apple Music
Avril Lavigne / 2007-04-17 / Import / Audio CD / 摇滚
7.9 ( 36865人评价 )

▶️ Apple Music
五月天 / 2005-11-18 / 专辑 / CD / 摇滚
9.3 ( 33223人评价 )

▶️ Apple Music
The Beatles / 2000 / 选集 / CD / 摇滚
9.5 ( 31020人评价 )

▶️ Apple Music
周杰伦 / 2008-10-09 / 专辑 / CD / 放克/灵歌/R&B
7.9 ( 59439人评价 )

▶️ Apple Music
Coldplay / 2005-06-07 / 专辑 / CD / 摇滚
8.6 ( 34819人评价 )

▶️ Apple Music
Adele / 2008-01-28 / Import / Audio CD / 放克/灵歌/R&B
8.6 ( 35491人评价 )

▶️ Apple Music
五月天 / 2003-11-11 / 专辑 / CD / 摇滚
9.1 ( 33602人评价 )

▶️ Apple Music
孙燕姿 / 2000-06-08 / 专辑 / CD / 流行
9.1 ( 34442人评价 )

nil
陈奕迅 / 2010-03-12 / EP / CD+DVD / 流行
8.9 ( 32688人评价 )

▶️ Apple Music
陈绮贞 / 2008-07-13 / 单曲 / CD / 流行
8.6 ( 29389人评价 )

▶️ Apple Music
田馥甄 / 2011-09-02 / 专辑 / CD / 流行
8.4 ( 35566人评价 )

梁静茹 / 2006-10-06 / 专辑 / CD / 流行
8.2 ( 34393人评价 )

▶️ Apple Music
王菲 / 2002 / 选集 / CD / 流行
9.5 ( 35275人评价 )

▶️ Apple Music
陈奕迅 / 2011-02-22 / EP / CD / 流行
8.8 ( 31725人评价 )

▶️ Apple Music
Norah Jones / 2002 / 专辑 / CD / 爵士
8.9 ( 30541人评价 )

▶️ Apple Music
朴树 / 2014-07-16 / 单曲 /
数字(Digital) / 原声 9.1 ( 79295人评价 )

nil
陈奕迅 / 2007-04-24 / 专辑 / CD / 流行
8.9 ( 37928人评价 )

▶️ Apple Music
Green Day / 2009-05-15 / 专辑 / CD / 摇滚
8.7 ( 30578人评价 )

▶️ Apple Music
張懸 / 2012-08-10 / 专辑 / CD / 流行
9.1 ( 39638人评价 )

▶️ Apple Music
王菲 / 1998 / 专辑 / CD / 流行
9.4 ( 39092人评价 )

▶️ Apple Music
陈绮贞 / 2007-05-18 / 演唱会/Live / CD DVD / 民谣
9.3 ( 26500人评价 )

▶️ Apple Music
朴树 / 1999-1 / 专辑 / CD / 流行
9.4 ( 44055人评价 )

▶️ Apple Music
GALA / 2004 / 专辑 / CD / 摇滚
8.8 ( 30290人评价 )

▶️ Apple Music
孙燕姿 / 2002年1月 / 专辑 / CD / 流行
9.0 ( 29171人评价 )

▶️ Apple Music
李宗盛 Jonathan / 2007-09-28 / 专辑 / CD / 流行
9.6 ( 28244人评价 )

▶️ Apple Music
曹方 / 2007-11-20 / EP / CD / 流行
8.5 ( 27597人评价 )

▶️ Apple Music
窦唯 / 1994-10 / 专辑 / CD / 摇滚
9.4 ( 41855人评价 )

▶️ Apple Music
周杰倫,Terdsak Janpan,詹宇豪,陳承麒,黃婉琦,姚蘇蓉,黃俊郎,江語晨,長榮交響樂團 / 2007-08-13 / Soundtrack / CD / 原声
9.1 ( 45209人评价 )

▶️ Apple Music
梁静茹 Fish / 2005-9-16 / 专辑 / CD / 流行
8.3 ( 32166人评价 )

▶️ Apple Music
James Blunt / 2007-09-18 / Import / Audio CD / 流行
8.6 ( 26484人评价 )

▶️ Apple Music
飞儿乐团 F.I.R. / 2004-04-29 / 专辑 / CD / 摇滚
8.9 ( 41045人评价 )

▶️ Apple Music
陈奕迅 / 2009-09-23 / 专辑 / CD / 流行
7.8 ( 29505人评价 )

▶️ Apple Music
Linkin Park / 2007-05-15 / 专辑 / CD / 摇滚
8.4 ( 27501人评价 )

▶️ Apple Music
蔡健雅,Tanya / 2007-10-19 / 专辑 / CD / 流行
8.6 ( 28081人评价 )

▶️ Apple Music
Adele / 2011-01-24 / 单曲 /
数字(Digital) / 放克/灵歌/R&B 9.5 ( 40674人评价 )

nil
苏打绿 / 2006-09-18 / EP / CD / 流行
9.0 ( 27165人评价 )

▶️ Apple Music
Pink Floyd / 1973 / 专辑 / 黑胶 / 摇滚
9.5 ( 45690人评价 )

▶️ Apple Music
王菲 / 2001 / 专辑 / CD / 流行
9.2 ( 31937人评价 )

▶️ Apple Music
逃跑计划 / 2011-04-12 / 单曲 /
数字(Digital) / 摇滚 9.2 ( 60184人评价 )

nil
GALA / 2011-03-24 / 专辑 / CD / 摇滚
8.9 ( 36650人评价 )

▶️ Apple Music
莫文蔚 / 2010-07-26 / 专辑 / CD / 流行
8.0 ( 27226人评价 )

▶️ Apple Music
陈奕迅 / 2003 / 专辑 / CD / 流行
9.1 ( 27667人评价 )

▶️ Apple Music
宋冬野 / 2013-08-26 / 专辑 / CD / 民谣
8.9 ( 46048人评价 )

▶️ Apple Music
宇多田ヒカル / 2008-05-21 / CD IMPORT / Audio CD / 流行
9.3 ( 26585人评价 )

陈绮贞 / 2002-08-02 / 专辑 / CD / 流行
9.3 ( 30585人评价 )

▶️ Apple Music
The Innocence Mission / 2004 / 专辑 / CD / 民谣
8.5 ( 24692人评价 )

▶️ Apple Music
Timbaland,OneRepublic / 2007-11-06 / Single / Audio CD / 放克/灵歌/R&B
9.2 ( 32971人评价 )

▶️ Apple Music
王菲 / 2009-06-25 / 选集 / CD / 流行
9.4 ( 26218人评价 )

▶️ Apple Music
周杰伦 / 2010-05-14 / 专辑 / CD / 流行
7.8 ( 41601人评价 )

▶️ Apple Music
孙燕姿 / 2002-5-21 / 专辑 / CD / 流行
8.8 ( 27012人评价 )

▶️ Apple Music
李志 / 2004-12 / 专辑 / CD / 民谣
9.0 ( 29948人评价 )

nil
陈奕迅 / 2006 / 专辑 / CD / 流行
9.3 ( 29133人评价 )

▶️ Apple Music
五月天 / 2011-12-20 / 专辑 / CD / 流行
9.2 ( 26729人评价 )

▶️ Apple Music
陶喆 / 2003-08-08 / 选集 / CD / 流行
9.2 ( 26071人评价 )

▶️ Apple Music
Maroon 5 / 2007-05-22 / 专辑 / CD / 流行
8.4 ( 25476人评价 )
▶️ Apple Music
张悬 / 2008-10-20 / Bootleg / 数字 / 民谣
8.5 ( 26320人评价 )

nil
蔡健雅 Tanya Chua / 2003-06-00 / 专辑 / CD / 流行
8.7 ( 26152人评价 )

▶️ Apple Music
王菲 / 1996 / Audio CD / 流行
9.4 ( 37119人评价 )

▶️ Apple Music
自然卷 / 2004 / 专辑 / CD / 民谣
8.3 ( 24874人评价 )

nil
刘若英 / 2010-04-16 / 专辑 / CD / 流行
7.9 ( 24721人评价 )

▶️ Apple Music
Rosie Thomas / 2007-03-13 / 专辑 / Audio CD / 民谣
8.8 ( 23227人评价 )

▶️ Apple Music
苏打绿 / 2008 / 引进版 / CD
9.2 ( 23965人评价 )

Lily Allen / 2009-02-09 / 专辑 / Audio CD / 流行
8.2 ( 24122人评价 )

▶️ Apple Music
手嶌葵 / 2008-03-05 / Import / CD / 流行
9.3 ( 24179人评价 )

▶️ Apple Music
李志 / 2009-10-16 / 专辑 / CD / 民谣
8.9 ( 32777人评价 )

▶️ Apple Music
大乔小乔 / 2007-07-12 / 平装版 / CD / 民谣
8.3 ( 23581人评价 )

▶️ Apple Music
范晓萱 / 2004 / 专辑 / CD / 流行
8.7 ( 22928人评价 )

▶️ Apple Music
卡奇社 / 2007-04-20 / 专辑 / CD / 流行
8.2 ( 24481人评价 )

▶️ Apple Music
冯曦妤 / 2008-11-20 / 专辑 / CD / 流行
8.5 ( 23442人评价 )

▶️ Apple Music
Coldplay / 2000-07-03 / EP / Audio CD / 摇滚
9.5 ( 37346人评价 )

▶️ Apple Music
Keane / 2004 / 专辑 / Audio CD / 摇滚
8.9 ( 22915人评价 )

▶️ Apple Music
陈奕迅 / 2005-06-07 / 专辑 / CD+DVD / 流行
9.4 ( 29071人评价 )

▶️ Apple Music
Maximilian Hecker / 2005 / Import / Audio CD / 摇滚
8.8 ( 21513人评价 )

▶️ Apple Music
久石譲(Joe Hisaishi),杉並児童合唱団,井上杏美 / 1993-12-21 / Soundtrack / Audio CD / 原声
9.6 ( 26336人评价 )

▶️ Apple Music
崔健 / 1989 / 专辑 / CD / 摇滚
9.4 ( 31792人评价 )

▶️ Apple Music
棉花糖,katncandix2 / 2009-05-01 / 专辑 / CD / 民谣
8.0 ( 22804人评价 )

▶️ Apple Music
好妹妹乐队 / 2012-07-01 / 专辑 / CD / 民谣
8.9 ( 23906人评价

▶️ Apple Music
陈绮贞 / 1998-07-14 / 专辑 / CD / 民谣
9.1 ( 24812人评价 )

▶️ Apple Music
方大同 / 2007-12-28 / 专辑 / CD / 放克/灵歌/R&B
8.4 ( 23802人评价 )

▶️ Apple Music
方大同 / 2006-12 / 专辑 / CD / 流行
8.7 ( 25456人评价 )

▶️ Apple Music
逃跑计划 / 2014-12-09 / 专辑 / CD / 摇滚
9.0 ( 26819人评价 )

盧廣仲,卢广仲 / 2009-10-30 / 专辑 / CD / 民谣
7.9 ( 22531人评价 )

▶️ Apple Music
Nirvana / 2002-10-29 / Extra tracks / Audio CD / 摇滚
9.3 ( 22711人评价 )

▶️ Apple Music
nil
Coldplay / 2002 / 专辑 / Audio CD / 摇滚
8.8 ( 25535人评价 )
▶️ Apple Music
The Velvet Underground,Nico / 1967-04 / 专辑 / CD / 摇滚
9.3 ( 31513人评价 )

▶️ Apple Music
Eminem,Rihanna / 2010-08-20 / Single / Audio CD / 说唱
9.3 ( 28411人评价 )

nil
王菲 / 1994 / 专辑 / CD / 流行
9.4 ( 29503人评价 )

▶️ Apple Music
Original Soundtrack / 2009-03-30 / Import / Soundtrack / CD / 原声
9.3 ( 20223人评价 )

nil
Oasis / 1995 / 专辑 / CD / 摇滚
9.3 ( 27765人评价 )

▶️ Apple Music
陈绮贞 / 2007-02-08 / 单曲 / Audio CD / 民谣
8.7 ( 21369人评价 )

nil
Salyu / 2001 / 专辑 / CD / 原声
9.1 ( 22021人评价 )

▶️ Apple Music
Evanescence / 2003 / 专辑 / Audio CD / 摇滚
8.5 ( 21152人评价 )

▶️ Apple Music
黑豹 / 1992-12-01 / 专辑 / CD / 摇滚
9.3 ( 27065人评价 )

▶️ Apple Music
苏打绿 / 2010-08-27 / 视频 / CD+DVD / 流行
9.0 ( 23902人评价 )

▶️ Apple Music
梁静茹 / 2003年3月 / 专辑 / CD / 流行
9.0 ( 22492人评价 )

▶️ Apple Music
Suede / 1993 / 专辑 / CD / 摇滚
9.0 ( 24460人评价 )

▶️ Apple Music
Radiohead / 1995 / 专辑 / CD / 摇滚
9.3 ( 30381人评价 )

▶️ Apple Music
林海 / 2004 / 专辑 / CD / 轻音乐
9.4 ( 21797人评价 )

▶️ Apple Music
陈奕迅 / 2011-11-11 / 专辑 / CD / 流行
8.1 ( 24284人评价 )

▶️ Apple Music
彭坦 / 2007-07-23 / 专辑 / CD / 流行
8.2 ( 22022人评价 )

▶️ Apple Music
雷光夏 / 2006-12-01 / 专辑 / CD / 民谣
8.9 ( 21264人评价 )

▶️ Apple Music
范晓萱 / 1999-11-1 / 国语 / CD / 流行
8.8 ( 24064人评价 )

▶️ Apple Music
五月天 / 2001-07-06 / 专辑 / CD / 摇滚
9.3 ( 25704人评价 )

▶️ Apple Music
Owl City / 2008-03-18 / Import / CD / 流行
8.4 ( 20707人评价 )

▶️ Apple Music
李志 / 2009-01-22 / 专辑 / 数字 / 民谣
9.2 ( 23029人评价 )

nil
The Beatles / 1990-10-25 / Enhanced / Audio CD / 摇滚
9.5 ( 25678人评价 )

▶️ Apple Music
Lily Allen / 2006 / Import / Audio CD / 流行
8.4 ( 20280人评价 )

▶️ Apple Music
林宥嘉 / 2012-06-22 / 专辑 / CD / 流行
8.2 ( 24828人评价 )

▶️ Apple Music
牛奶@咖啡 / 2008-03-18 / 专辑 / CD / 流行
7.8 ( 27754人评价 )

▶️ Apple Music
梁静茹 / 2004 / 专辑 / CD / 流行
8.1 ( 25599人评价 )

▶️ Apple Music
戴佩妮 / 2009-05-16 / 专辑 / CD+DVD / 流行
7.7 ( 21671人评价 )

nil
王菲 / 2010-11-05 / 单曲 / CD / 民谣
9.0 ( 26139人评价 )

nil
Daniel Powter / 2008-10-14 / 专辑 / Audio CD / 流行
8.5 ( 19397人评价 )

▶️ Apple Music
五月天 / 2006 / 视频 / DVD / 流行
9.3 ( 20016人评价 )

▶️ Apple Music
曲婉婷 / 2012-07-01 / 专辑 / CD / 流行
8.1 ( 21550人评价 )

▶️ Apple Music
王菲 / 1997-09-30 / 专辑 / CD / 流行
9.4 ( 30662人评价 )

nil
汪峰 / 2009-07-25 / 专辑 / CD / 摇滚
8.8 ( 20801人评价 )

nil
莫文蔚 / 2002-04-29 / 专辑 / CD / 流行
8.8 ( 22357人评价 )

▶️ Apple Music
Maroon 5 / 2002 / 专辑 / Audio CD / 流行
8.8 ( 21946人评价 )

▶️ Apple Music
Amy Winehouse / 2006-10-30 / 专辑 / Audio CD / 放克/灵歌/R&B
8.9 ( 22840人评价 )

▶️ Apple Music
陈绮贞 / 2001-11-09 / Demo / CD / 流行
9.2 ( 19720人评价 )

nil
孙燕姿 / 2014-02-27 / 专辑 / CD / 流行
8.7 ( 32216人评价 )

▶️ Apple Music
Mariah Carey / 2008-04-16 / 专辑 / CD / 放克/灵歌/R&B
8.6 ( 21245人评价 )

▶️ Apple Music
Damien Rice / 2006-11-27 / 单曲 / Audio CD / 民谣
9.4 ( 18711人评价 )
▶️ Apple Music
陈珊妮 / 2008-11-22 / 专辑 / CD / 流行
8.3 ( 20153人评价 )

▶️ Apple Music
郑钧 / 1994 / 专辑 / CD / 摇滚
8.9 ( 24139人评价 )

▶️ Apple Music
张震岳 / 2004-06-24 / 选集 / CD / 流行
9.0 ( 20320人评价 )

▶️ Apple Music
朱玫玲,董運昌,王雁盟,何真真 / 2004/04/26 / CD / 轻音乐
9.2 ( 17459人评价 )

▶️ Apple Music
Green Day / 2009-07-14 / Single / Audio CD / 流行
9.2 ( 20417人评价 )

nil
蔡依林 Jolin Tsai / 2003-03-07 / 专辑 / CD / 流行
8.1 ( 34974人评价 )

▶️ Apple Music
五月天 / 2011-12-20 / 专辑 / CD / 流行
9.2 ( 20376人评价 )

▶️ Apple Music
Oasis / 1994-08-30 / 专辑 / CD / 摇滚
9.2 ( 24503人评价 )

▶️ Apple Music
宇多田ヒカル / 1999 / 专辑 / CD / 流行
9.2 ( 24302人评价 )

▶️ Apple Music
张惠妹 / 2009-06-26 / 专辑 / CD / 流行
8.1 ( 23719人评价 )

▶️ Apple Music
王力宏 Leehom Wang / 2008-12-26 / 专辑 / CD / 流行
7.3 ( 23629人评价 )

▶️ Apple Music
The xx / 2009-08-17 / 专辑 / CD / 摇滚
8.9 ( 22501人评价 )

▶️ Apple Music
莫文蔚 / 2009-06-23 / 专辑 / CD+DVD / 流行
8.1 ( 20095人评价 )

▶️ Apple Music
Tizzy Bac / 2009-02-13 / 专辑 / CD / 流行
8.2 ( 19128人评价 )

▶️ Apple Music
五月天 / 2003年4月17日 / 专辑 / CD / 流行
9.4 ( 21570人评价 )

▶️ Apple Music
萧敬腾 / 2009-07-17 / 专辑 / CD / 流行
7.9 ( 24245人评价 )

▶️ Apple Music
Lady Gaga / September 23, 2008 / Single / Audio CD / 流行
8.8 ( 25206人评价 )

▶️ Apple Music
唐朝 / 1992-12 / CD+DVD / CD / 摇滚
9.1 ( 22391人评价 )

▶️ Apple Music
周杰伦 / 2003-12-1 / EP / 音乐CD / 流行
9.1 ( 29108人评价 )

▶️ Apple Music
林俊杰 / 2010-12-08 / 专辑 / CD / 流行
8.3 ( 34938人评价 )

▶️ Apple Music
]]>





















 上海解封后,摄于北外滩酒店
上海解封后,摄于北外滩酒店
















 image from wife
image from wife
 image from pixabay.com
image from pixabay.com
 image from Twitter
image from Twitter image from pixabay.com
image from pixabay.com