
加入沪江不久,我就被扔到一个将集团 SQL Sever 的数据库迁移到 MySQL 的项目里,
同时伴随进行的还有 .net 系统迁移到 Java 系统。
在这个过程中我发现了一个很有趣的现象:历史遗留的 .net 项目中,
几乎所有的 SQL 中都会使用一个关键字:nolock。
这让我很困惑,nolock 的字面意思是对当前技术不使用锁技术,为什么要这样用呢?
我找了一个范例如下:
SELECT [id]
FROM [dbo].[foos] WITH(nolock)
WHERE aField = 42
AND bField = 1
作为横向支持工程师,开发工程师会问我:「数据库即将从 SQL Server
迁移到 MySQL,我们编码中还需要使用 nolock 么?
MySQL 里面对应的写法是什么?」。
我并没有 SQL Server 的生产环境使用经验,一时间无法回答。
于是课后做相关知识学习,这里就是这次学习的一点成果。
这个问题将被拆解成三个小问题进行回答:
nolock是什么?- 为什么会需要在每个 Query 语句使用
nolock? - MySQL 的对应写法是什么?
让我们一个一个来看。
第一个问题:nolock 是什么?
nolock 是 SQL Server 的一个关键字,这类关键字官方将其称之为 Hints。
Hints 的设计目的是为了能够让 SQL 语句在运行时,动态修改查询优化器的行为。
在语法上,Hints 以 WITH 开头。除了 WITH(nolock),
还有 TABLOCK / INDEX / ROWLOCK 等常见的 Hints。
让我们仔细看看 MSDN 文档上的解释:
nolock的作用等同于READUNCOMMITTED
READUNCOMMITTED 这是一种 RDBMS 隔离级别。
使用 nolock 这个关键词,可以将当前查询语句隔离级别调整为 READ UNCOMMITTED。
计算机基础好的同学,应该对 READUNCOMMITTED 这个关键词还有印象。
而基础不扎实的同学,也许只是觉得这个关键词眼熟,但是讲不清楚这是什么。
如果阅读这句话完全没有理解困难,那恭喜你,你可以直接跳到下一节了。
其他朋友就跟随我继续探索一下 RDMBS 的世界,复习一下隔离级别相关的知识。
隔离级别
SQL 92 定义了四个隔离级别 (Isolation (database systems) - Wikipedia), 其隔离程度由高到低是:
- 可序列化(Serializable)
- 可重复读(Repeatable reads)
- 提交读(Read committed)
- 未提交读(Read uncommitted)
单单将这几个技术名词简单地罗列出来并没有什么意义,还有这几个问题需要搞清楚:
- 隔离级别解决什么问题?
- 为什么存在多种隔离级别?
- 我们所谓的隔离级别从高到低,是什么含义,如何逐层降低的?
首先是「隔离级别解决什么问题?」, 用通俗的语言描述就是:加一个针对数据资源的锁,从而保证数据操作过程中的一致性。
这是最简单的实现方式,过于粗暴的隔离性将大幅降低性能, 多种隔离级别就是是为了取得两者的平衡。
接下来我们来回答第二个问题「为什么存在多种粒度的隔离级别?」 这其实是一个需求和性能逐步平衡的过程,
我们逐层递进,将隔离级别由低到高逐层面临进行分析。
Read Uncommitted
Read Uncommitted 这个隔离级别是最低粒度的隔离级别, 如同它的名字一般,它允许在操作过程中不会锁,从而让当前事务读取到其他事务的数据。

如上图所示,在 Transaction 2 查询时候,Transaction 1 未提交的数据就已经对外暴露。 如果 Transaction 1 最后 Rollback 了,那么 Transaction 读取的数据就是错误的。
「读到了其他事务修改了但是未提交的数据」即是脏读。
Read Committed
想要避免脏读,最简单的方式就是在事务更新操作上加一把写锁, 其他事务需要读取数据时候,需要等待这把写锁释放。
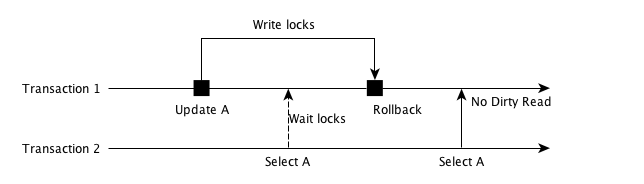
如上图所示,Transaction 1 在写操作时候,对数据 A 加了写锁, 那么 Transaction 2 想要读取 A,就必须等待这把锁释放。 这样就避免当前事务读取其他事务的未提交数据。
但是除了脏读,一致性的要求还需要「可重复读」,即 「在一个事务内,多次读取的特定数据都必须是一致的 (即便在这过程中该数据被其他事务修改)」。
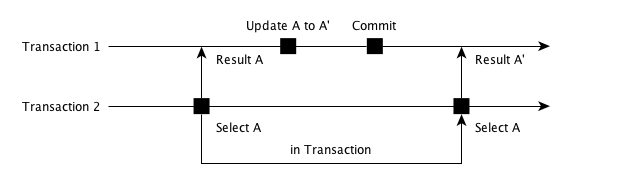
上图就是没能保证「可重复度」,Transaction 2 第一次读取到了数据 A, 然后 Transaction 1 对数据 A 更新到 A’,那么当 Tranction 2 再次读取 A 时候, 它本来期望读到 A,但是却读到了 A’,这和它的预期不相符了。 解决这个问题,就需要提升隔离级别到「Repeatable Read」。
Repeatable Read
这个名字非常容易理解,即保障在一个事务内重复读取时, 始终能够读取到相同的内容。来看图:
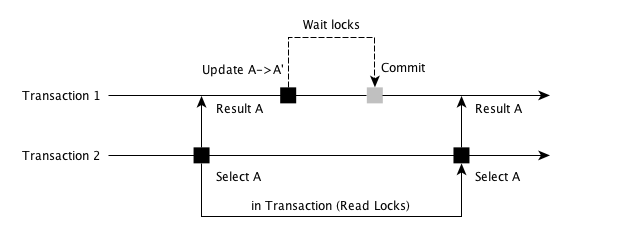
如上所示,当 Transation 2 读取 A 时候,会同时加上一把 Read Lock, 这把锁会阻止 Transaction 1 将 A 更新为 A’,Transaction 1 要么选择等待, 要么就选择结束。
当我们将隔离级别升到这里是,似乎已经完美无缺了。 不管是写入还是读取,我们都可以保证数据的一致性不被破坏。 但是其实还有漏洞:新增数据的一致性!
上述的三个隔离级别,都是对特定的一行数据进行加锁, 那假如将要更新的数据还没有写入数据库,如何进行加锁呢? 比如自增表的新键,或者现有数据内的空缺 Key?
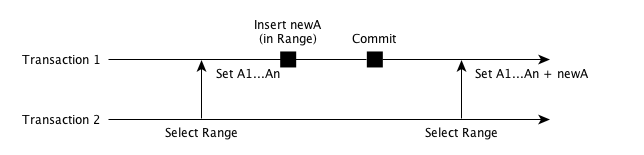
如图所示,在上述操作中,Transaction 2 查询了一个范围 Range 之后,Transaction 1 在这个范围内插入了一条新的数据。此时 Transaction 2 再次进行范围查询时候, 会发现查询到的 Range 和上次已经不一样了,多了一个 newA。
这就是最高隔离级别才能解决的「幻影读」: 当两个完全相同的查询语句执行得到不同的结果集, 这常常在范围查询中出现。
Serializable
从字面意思看,该隔离级别需要将被操作的数据加锁加一把锁。 任何读写操作都需要先获得这把锁才能进行。如果操作中带 WHERE 条件, 还需要将 WHERE 条件相关的范围全部加锁。
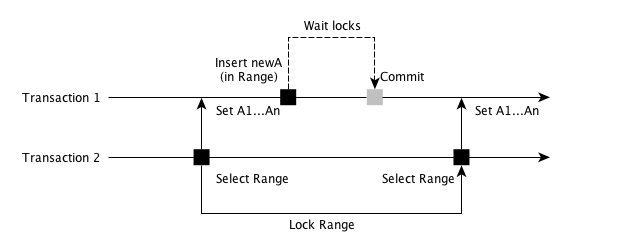
如图所示,在 Transaction 2 操作过程中,会对 Range 进行加锁, 此时其他事务无法操作其中的数据,只能等待或者放弃。
DB 的默认隔离级别
现在我们已经理解了隔离级别,那么「SQL Server 默认使用的隔离级别是什么呢?」 根据 Customizing Transaction Isolation Level 这个文档描述,SQL Server 默认隔离级别是 READ COMMITTED。
MySQL InnoDB 的默认隔离级别可以在 MySQL :: MySQL 5.7 Reference Manual :: 14.5.2.1 Transaction Isolation Levels 查询到,是 Read-Repeatable。
隔离级别并没有最好之说,越高隔离级别会导致性能降低。 隔离级别的设定需要考虑业务场景。
第二个问题:为什么要使用 nolock?
我们已经知道 nolock 的作用是动态调整隔离级别。
那为什么在 SQL Server 的 Query 操作中,需要启用 nolock 呢?
我问了几个工程师,他们都语焉不详,或者是很泛泛地说:禁用读写锁,可以提升查询性能。
此时我产生了困惑:「那么此时的数据一致性就不需要考虑了么?
我们的数据库,已经到了需要禁用锁的程度来进行优化了么?」
我于是自己去探索,想知道为何广泛使用 nolock 会成为一个「最佳实践」?
由于时代久远,我只能追述到一些相关信息,比如
Top 10 SQL Server Integration Services Best Practices | SQL Server Customer Advisory Team
中提到 「Use the NOLOCK or TABLOCK hints to remove locking overhead.」
但这个是针对于 SSIS 查询器,并不是针对业务内部使用。
反而能找到一大堆的文档,在反对使用 nolock 这个关键字。
继续追查下去,还从蛛丝马迹中寻找到一个使用 nolock 的理由,
SQL Server 默认是 Read Committed,
更新操作会产生排它锁,会 block 这个资源的查询操作,
已插入但未提交的数据主键也会产生一个共享锁,
而此时则会 block 这张表的全表查询和 Insert 操作。
为了避免 Insert 被 Block,就会推荐使用 nolock。
为了验证这是原因,我做一些 nolock 测试。
nolock 测试
检查当前 SQL Server 隔离级别,确认隔离级别是默认的 Read Committed:
SELECT CASE transaction_isolation_level
WHEN 0
THEN 'Unspecified'
WHEN 1
THEN 'ReadUncommitted'
WHEN 2
THEN 'ReadCommitted'
WHEN 3
THEN 'Repeatable'
WHEN 4
THEN 'Serializable'
WHEN 5
THEN 'Snapshot' END AS TRANSACTION_ISOLATION_LEVEL
FROM sys.dm_exec_sessions
WHERE session_id = @@SPID
-- ReadCommitted
创建表,初始化数据:
CREATE TABLE foos (
id BIGINT NOT NULL,
value NCHAR(10) NULL,
CONSTRAINT pk PRIMARY KEY clustered (id)
);
INSERT INTO foos (id, value) VALUES (1, '1'), (2, '2');
在 Transaction 1 中发起 Update 操作(INSERT / DELETE 同理),但是并不做 Commit 提交:
BEGIN TRANSACTION;
INSERT INTO foos (id, value) VALUES (3, '3');
开启一个新的 Session,发起全表查询和新增 PK 查询操作:
SELECT * FROM foos;
SELECT * FROM foos WHERE id = 4;
不出所料,此时查询果然会被 Block 住。
MVCC
并发控制的手段有这些:封锁、时间戳、乐观并发控制、悲观并发控制。 SQL Server 在 2005 后,引入了 MVCC(多版本控制)。 如果最终数据是一致,会允许数据写入,否则其他事务会被阻止写入。 那么 MVCC 引入是否可以解决 Insert 数据的锁问题? 同样,我做了以下测试:
查询 SQL Server 使用启用 MVCC ALLOW_SNAPSHOT_ISOLATION:
SELECT name, snapshot_isolation_state FROM sys.databases;
使用 T-SQL 启用测试表的 SNAPSHOT_ISOLATION:
ALTER DATABASE HJ_Test3D SET ALLOW_SNAPSHOT_ISOLATION ON;
接着重复上面里面的 Insert 试验,依然被 Block 住。 看来 MVCC 并不能解决 Insert 锁的问题。
SQL Server 2005 之后还需要使用 nolock 么?
从官方文档和上文测试可以看到,在 Insert 时候,由于排它锁的存在,
会导致 SELECT ALL 以及 SELECT 新插入数据的相关信息被锁住。
在这两种情景下面是需要使用 nolock 的。
除此之外,有这么几类场景可以使用 nolock:
- 在 SSIS 查询器中进行数据分析,不需要精准数据
- 历史数据进行查询,没有数据更新操作,也不会产生脏数据
我们需要思考一下,性能和数据一致性上的权衡上,
我们是否愿意放弃数据一致性而为了提高一丝丝性能?
以及我们有多少场景,会频繁使用 SELECT ALL 操作而没有查询条件?
微软官方在 2008 的特性列表里面,明确地指出 nolock 特性未来会在某个版本被废除:
Specifying NOLOCK or READUNCOMMITTED in the FROM clause of an UPDATE or DELETE statement.
而改为推荐:
Remove the NOLOCK or READUNCOMMITTED table hints from the FROM clause.
事实上,我听过不少团队会禁止在生产环境使用不带 WHERE 条件的 SQL。 那在这种模式下,产生相关的问题的几率也就更小了。 如果有很高的并发需求,那需要考虑一下是否需要其他优化策略:比如使用主从分离、 Snapshot 导出、流式分析等技术。
第三个问题:MySQL 的对应写法是什么?
终于轮到 MySQL 的讨论了。MySQL,InnoDB 天生支持 MVCC,
并且支持 innodb_autoinc_lock_mode AUTO_INCREMENT Handling in InnoDB。
这样可以避免 Insert 操作锁住全局 Select 操作。
只有在同时 Insert 时候,才会被 Block 住。
innodb_autoinc_lock_mode 支持几种模式:
- innodb_autoinc_lock_mode = 0 (“traditional” lock mode)
- 涉及auto-increment列的插入语句加的表级AUTO-INC锁,只有插入执行结束后才会释放锁
- innodb_autoinc_lock_mode = 1 (“consecutive” lock mode)
- 可以事先确定插入行数的语句,分配连续的确定的 auto-increment 值
- 对于插入行数不确定的插入语句,仍加表锁
- 这种模式下,事务回滚,auto-increment 值不会回滚,换句话说,自增列内容会不连续
- innodb_autoinc_lock_mode = 2 (“interleaved” lock mode)
- 同一时刻多条 SQL 语句产生交错的 auto-increment 值
这里也做了相应的测试。首先检查数据库隔离级别和 innodb_autoinc_lock_mode 模式:
SELECT @@global.tx_isolation, @@session.tx_isolation, @@tx_isolation;
SHOW variables LIKE 'innodb_autoinc_lock_mode';
检查后发现都是 Repeatable Read,innodb_autoinc_lock_mode 模式是 1。
然后创建测试表:
CREATE TABLE `foos` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8;
在 Transaction 1 中 Insert 数据:
START TRANSACTION;
INSERT INTO foos (name) VALUES ("a");
在 Transaction 2 中 Select 数据,可以正常查询:
SELECT * FROM foos;
在 Transaction 2 中 Insert 数据,会被 Block 住:
START TRANSACTION;
INSERT INTO foos (name) VALUES ("a");
这个测试可以证明 MySQL 可以在 innodb_autoinc_lock_mode=1 下,
Insert 同时 Query 不会被 Block,
但是在另外一个事务中 Insert 会被 Block。
结论是,由于 innodb_autoinc_lock_mode 的存在,MySQL 中可以不需要使用 nolock
关键词进行查询。
回顾一下
本文着重去回答这么几个问题:
- 为什么要用
noloc? - 为什么要改变隔离级别?
- 为什么 MySQL 不需要做类似的事情?
虽然只凑足了三个 「为什么」 的排比, 但是聪明的读者仍然会发现,我是使用了著名的 五个为什么 方法思考问题。 通过使用这个方法,我们最后不但打破了老旧的最佳实践,还了解了本质原理, 并找到了新的最佳实践。
希望读者朋友在遇到困难时候,多问几个为什么,多抱着打破砂锅问到底的精神, 这样才能让每个困难成为我们成长的垫脚石。
相关资料
- 事务隔离 - 维基百科,自由的百科全书
- Table Hints (Transact-SQL) | Microsoft Docs
- Snapshot Isolation in SQL Server | Microsoft Docs
- sys.databases (Transact-SQL) | Microsoft Docs
- MySQL :: MySQL 5.7 Reference Manual :: 15.3 InnoDB Multi-Versioning
原文链接: 一个关于 nolock 的故事:深入理解数据库隔离级别 | Log4D
3a1ff193cee606bd1e2ea554a16353ee
欢迎关注我的微信公众号:窥豹
